Paper Sharing: Hallucination in LLMs
论文链接:Nature 2024 | Detecting hallucinations in large language models using semantic entropy
期刊/会议:Nature 2024
基础定义#
- LLM Hallucination: 指的是大语言模型生成与事实不符、或者没有依据的内容
虽然幻觉的定义已经扩展到更广泛的范围,但是这篇 Nature 的工作主要讨论虚假认知(confabulations),特征是模型以准确、武断的方式生成错误并且随机的信息。
Tip: 这里的“随机”是一个重要的特征,它指的是模型对同一个问题,在多次采样时会随机输出不同的答案(可能包含正确答案)。
What is the target of Sotorasib?
(Sotorasib 的作用靶点是什么?)
- KRAS G12C (正确)
- KRAS G12D (错误)
这意味着如下的“幻觉”不在讨论范围内:
- 在训练数据中广泛存在的错误信息、常见误会
- 模型由于追求 reward 而产生的欺骗性行为(See OpenAI:Why language models hallucinate?)
- 系统性错误(Systematic errors),模型推理、泛化失败产生的错误,即问题本身超出了模型能力or模型从未在训练数据中见过对应的知识
主要目标#
这篇文章主要目标是开发一种检测方法,对于给定的 prompt 和一个模型,在没有外部知识参与的情况下,判断该 prompt 在多大程度上会导致模型产生幻觉(随机的错误输出)。
Main Idea#
由于本篇论文的主要目标是检测随机的错误输出,因此一个最直观的思路是采用基于不确定性的度量方法。对于同一个 prompt,可以通过测量大模型多次采样输出的不确定性来判断该 prompt 是否会导致幻觉。
朴素熵(Naive Entropy)#
大模型输出不确定性可以通过最朴素的方法度量,即计算输出文本的熵(Entropy)。
具体来说,对于一个给定的 prompt x,可以多次采样模型的输出,得到一组输出文本 ${y_1, y_2, \ldots, y_n}$,随后计算每个 QA 对(x, y_i)在模型输出中的概率分布 P(y|x), (这可以通过计算每个输出文本的对数似然值(Log-Likelihood, LL)来实现),然后计算概率分布的熵来度量不确定性。
然而,朴素熵存在一个明显问题,即它无法区分模型输出的多样性和幻觉引起的不确定性,eg:
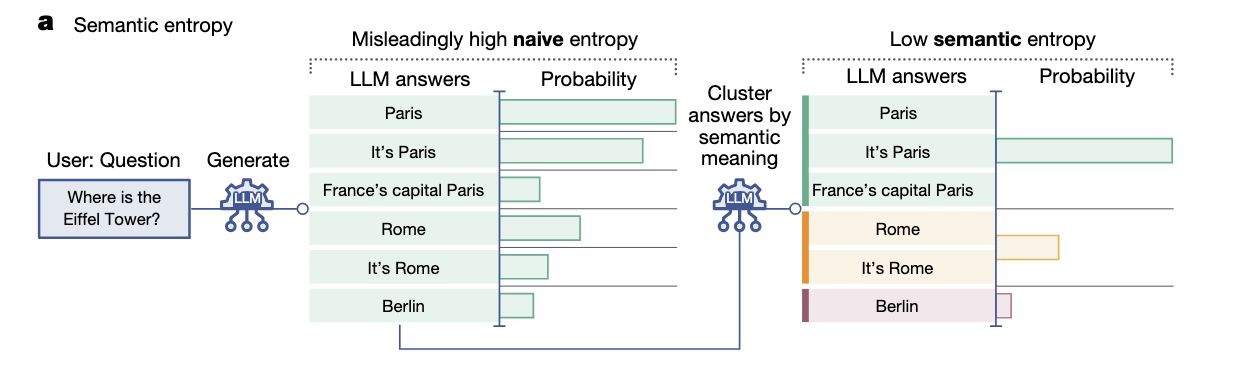
语义熵(Semantic Entropy)#
为了区分模型输出的多样性和幻觉引起的不确定性,论文提出了语义熵(Semantic Entropy)的概念,通过将输出的文本按照语义一致性进行聚类,然后计算聚类后的概率分布的熵。
这里采用的语义一致性聚类原则是双向蕴含(Bidirectional Entailment),即两个输出文本 y_i 和 y_j 被认为是语义一致的,当且仅当 y_i 蕴含 y_j 且 y_j 蕴含 y_i。这是一个经典的自然语言处理任务,可以用前大模型时代的自然语言推理(NLI)模型 eg:DeBERTa 或者最新的大模型来实现。
- 给定一个问题 p, 通过多次采样得到输出文本集合 ${y_1, y_2, \ldots, y_n}$。
- 对于文本集合,采用双向蕴含原则进行聚类,得到语义簇 ${C_1, C_2, \ldots, C_m}$。
- 计算每个语义簇的概率 $P(C_k) = \frac{|C_k|}{n}$。
- 计算语义熵 $H_{semantic}(p) = -\sum_{k=1}^{m} P(C_k) \log P(C_k)$。
实验#
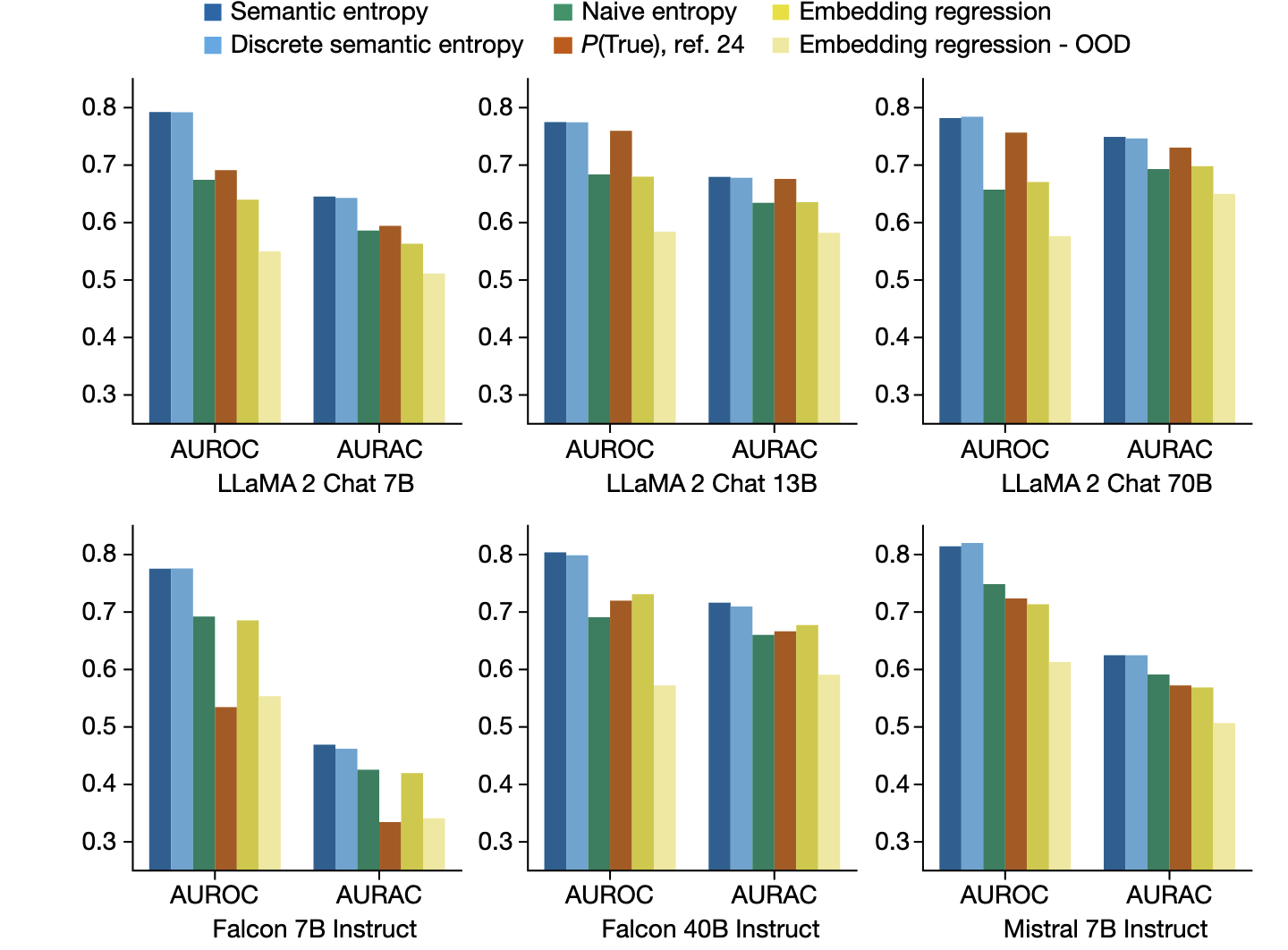
论文主要的实验指标数据是 AUROC 和 AUARC。
前者是通用的二分类评估指标:反映了直接以语义熵作为幻觉检测分数的有效性;
后者是一个新指标:反映了如果基于语义熵作为分类,删除高语义熵的样本后,模型在剩余样本上的性能提升。
主要的实验数据集是各种公共的 QA 数据集,TriviaQA (常识), BioASQ (生物医学), SQUAD (通用知识) 等。
拓展到长文本开放域生成#
如何检测长文本生成中出现的幻觉是一个更具有挑战性的问题。
本文包含一个拓展实验,用于评估 GPT-4 在长文本开放域生成任务中的幻觉程度,具体来说,论文要求 GPT-4 多个(21个)名人传记,这些“名人”是精心挑选的,他们有维基百科主页,但是主页的内容并不清晰。
评估方法:
- 使用 LLM 将名人传记分解为多个事实陈述,并人工标记这些陈述的真实性(真实/虚假)
- 使用 LLM 对每个事实陈述反向生成问题。
- 使用 GPT-4 多次采样回答这些问题,计算语义熵,并计算对应的 AUROC 和 AUARC。
实验结果#
总结#
这篇论文的主要贡献是提出了一种基于语义熵的幻觉检测方法,能够有效区分模型输出的多样性和幻觉引起的不确定性。
其次,这篇论文提出的长文本开放域生成幻觉检测方法是后面工作广泛 follow 的一个重要方法,See ACL 2025 outstanding paper: HALOGEN: Fantastic LLM Hallucinations and Where to Find Them
局限#
- 语义一致性聚类的准确性依赖于用于双向蕴含检测的模型的性能
- 计算开销大,尤其是长文本幻觉检测场景下,在需要多次采样和进行双向蕴含检测时
- 对于某些类型的幻觉可能不适用
论文链接:ICLR 2025 | Do I Know This Entity? Knowledge Awareness and Hallucinations in Language Models 期刊/会议:ICLR 2025
基础定义#
这篇论文关注的幻觉更加广泛,涵盖了模型生成的所有不准确或虚假的信息。
主要目标#
这篇论文主要目标是尝试从机制上理解大模型幻觉,特别是实体相关的幻觉。它尝试回答这样一个问题:模型在生成与特定实体相关的信息时,是否意识到它是否“知道”该实体的信息?
Main Idea#
稀疏自编码器(SAEs)是目前理解大模型内部机制的一个重要工具。它建立在这样的一个假设上,在 LLM 的高维空间中,大部分有意义的概念都是作为一个线性方向存在的。(这是一个常见且可信的假设,常见例子包括在 token 编码空间中,king - queen ≈ man - woman)
稀疏自编码器是常见的自编码器的反向版本,常见的 AutoEncoder 通过将输入映射到一个低维的潜在空间,然后再从潜在空间重建输入。而稀疏自编码器则是将输入映射到一个高维的稀疏空间(并施加稀疏性约束),然后再从高维稀疏空间重建输入。
具体技术原理 See Anthropic | Towards Monosemanticity: Decomposing Language Model Activations with Sparse Autoencoders,简单来说,通过构建同一个概念的正负方向样本集,在对应样本集上训练一个稀疏自编码器,就可以学习到该概念在模型空间中的线性方向。
eg: 通过构建“有害内容”和“无害内容”的样本集,可以训练一个稀疏自编码器来学习“有害”这个概念在模型空间中的线性方向;但是样本集必须足够大、足够准确(排除其他概念的干扰),才能准确定位一个概念。
实验#
- 构建数据集,作者从 Wikidata 中取了四类实体 (basketball) players, movies, cities, and songs. 然后要求目标模型预测这些实体的属性(例如,出生日期、导演、人口等),如果模型能至少预测两个属性,则该实体被标记为“已知”(known),否则标记为“未知”(unknown),介于中间状态的实体排除在外。

- 将实体名称输入到目标模型中,然后分析最后一个 token 的内部表示,并在模型的每一层都训练一个 SAEs 来尝试扫描“已知”和“未知”这两个概念的线性方向。
结果#
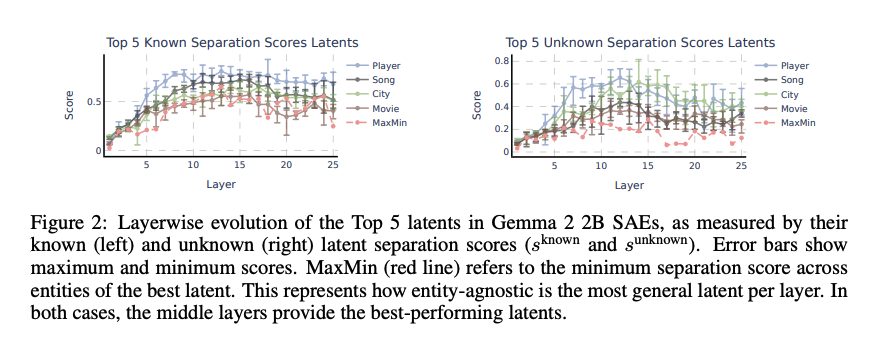
- 模型中存在一些特征对“已知-未知”这个概念有较强的区分能力,区分能力的指标是 Separation Score (SS),定义为已知实体在该特征上的激活均值减去未知实体在该特征上的激活均值。对于 Gemma 2 2B 的每一层,SS 分数的 Top 5 特征的 SS 分数如上图所示,可以看到存在一个总体趋势是先上升后下降,表明模型主要在中间层编码了“已知-未知”这个概念。
eg: 如果在模型的第10层,有一个特征对 80% 的已知球员激活,对 20% 的未知球员激活,那么该特征对球员的 SS_know 是 0.8 - 0.2 = 0.6。
- Max-Min SS:通过计算每一层中,每个已知实体的潜在分离变量对于其他未知实体的最小 SS 分数。如上图,它同样表现出先上升后下降的趋势。
eg:特征 A 在四种实体上的 SS 分数分别是 0.8, 0.5, 0.6, 0.7,那么 Min SS = 0.5,特征 B 在四种实体上的 SS 分数分别是 0.6, 0.4, 0.2, 0.7,那么 Min SS = 0.2;Max-Min SS 就是选择所有特征中 Min SS 最高的那个。某一层的 Max-Min SS 是 0.5,表明至少存在一个特征,他对四种已知实体的 SS 分数都不低于 0.5。
- 接下来,作者找到了所有层中,Min SS_known 和 Min SS_unknown 最高的两个特征,并研究了这两个特征对一些句子输入的激活情况,输入数据后,能激活该特征的 token 被高亮显示,深度表示激活强度。
 、
、
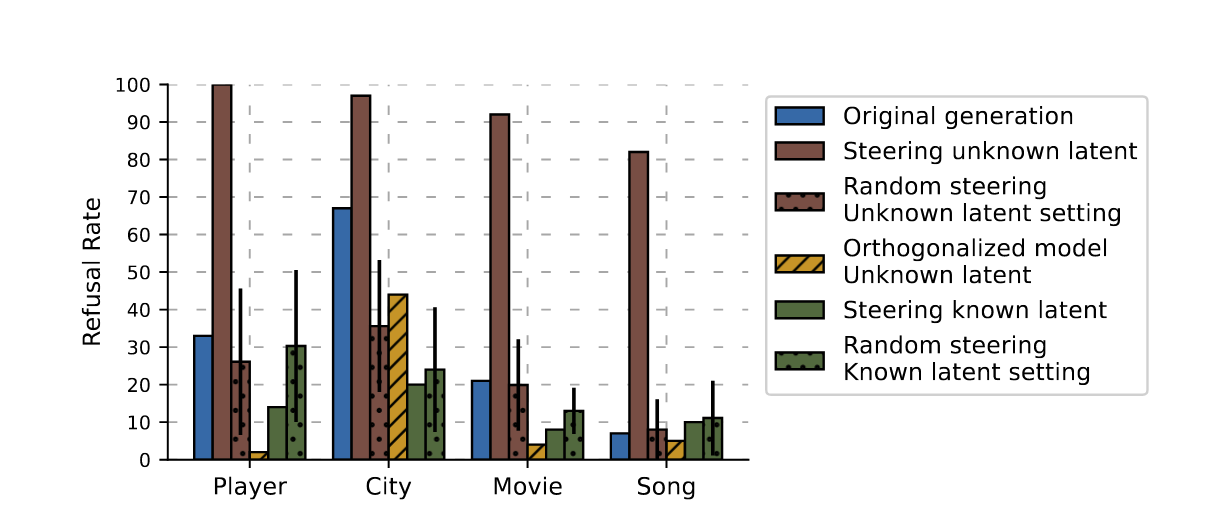
因果关系#
接着,作者基于相同的数据集数据,改编成了一个 Q-A 任务,要求模型回答实体的属性问题,并通过干预模型中“已知-未知”特征的激活,来观察对模型输出的影响,具体来说是对模型拒绝回答率的影响。
附加其他发现#
-
prior work 说明,当模型尝试回忆某个实体的信息时,下游的“属性提取”注意力头 (attribute extraction heads) 会重点关注实体名称的 token。论文发现,当模型“知道”某个实体时,这些注意力头的注意力分数会更高,而如果人为增强“未知”方向,这些注意力头的注意力分数会显著下降。
-
在 chat 模型中,作者发现一些似乎表示不确定性的 SAEs 特征,这些特征在即将给出错误答案(幻觉)的时候激活值更高,高于给出正确答案时,这是一种潜在的不用生成答案就能提前预知幻觉的机制,但需要进一步实验验证。
总结#
- 大模型内部存在一些特征,能够区分模型是否“知道”某个实体的信息。
- 通过干预这些特征的激活,可以影响模型的回答行为,其机制可能通过调控下游的属性提取注意力头实现。
- 可能存在一些表示不确定性的特征,这些特征在模型产生幻觉时激活更高。
值得关注#
- 主实验是在 2B 模型上实现的,似乎是因为这是一个 Anthropic 构建的评估套件,实验效果能否在大规模模型上复现?自己训练稀疏自编码器的成本大约如何?
- 论文中提到的额外发现(eg: 不确定性特征)是否可靠?是否能在更大模型上复现?